[대회] 2020 데이터 크리에이터 캠프 본선 최우수상

팀명 : 현상금사냥꾼(한국디지털미디어고)

대회에 참가하여 많은 것을 공부하고 경험해보게 된 좋은 계기가 되었다.
대회에서 제시된 문제는 이러했다.


주어진 데이터 셋의 형식은 이러했다.
pkl 파일로, 파이썬의 pickle 모듈을 사용하여 객체를 파일로 저장한 형태이다.
pandas의 read_pickle 함수를 이용하여 DataFrame 형태로 불러왔다.

데이터는 이런 구조로 이루어져있다.
팀원들과 문제를 이해하며 문제와 함께 제시된 예제를 분석하고 머신러닝을 통해 모델이 더 나은 예측을 할 수 있도록 만드는 것이 우리의 목표였다.
이 예제를 분석하고 개선시키기 위한 방안으로 우린 두 가지를 생각해냈다.
1. Logistic Regression / KNN 의 하이퍼 파라미터를 개선하는 방법
2. 다른 모델을 적용하는 방법
1. Logistic Regression / KNN 의 하이퍼 파라미터를 개선하는 방법
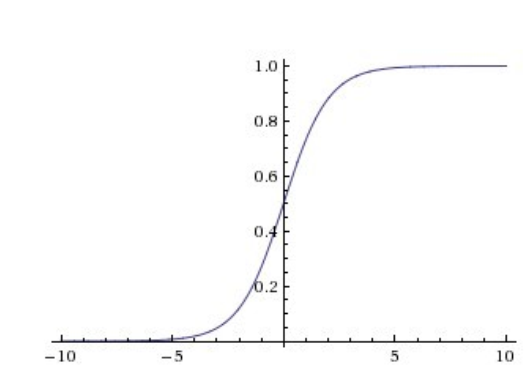
Logistic Regression 알고리즘은 특정 숫자를 기준으로 잡아,
이를 넘어서면 참 아니면 거짓(0,1)을 제공한다.
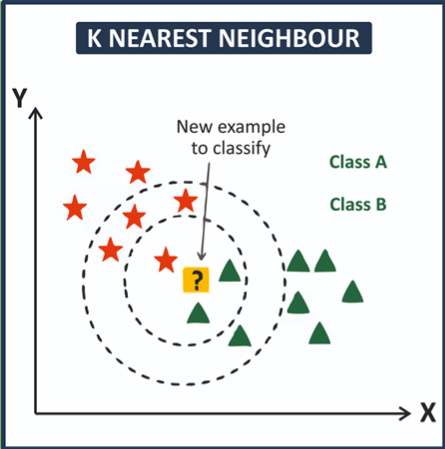
KNN 알고리즘은 새로운 값이 들어왔을 때,
이와 가장 가까운데에 위치한 다른 값들을 통하여 라벨(y데이터)을 유추해내는 방법이다.
위의 파라미터에 사용되는 solver 를 saga 방식으로 바꿔보고, sag, liblinear 등 여러가지 solver 종류와 원리를 알아보며 시도를 해보았지만 Accuracy(정확도)는 나아지지 않았다.
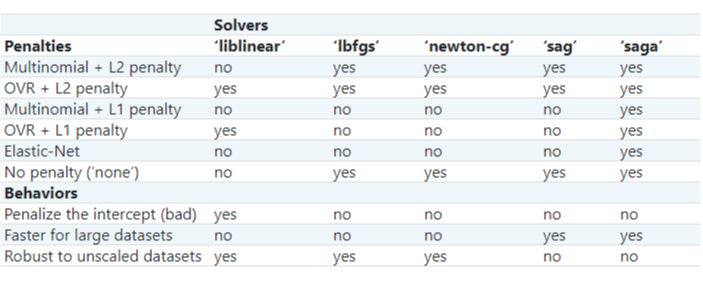

오히려 예제에서 제시된 모델보다 더 낮은 정확도를 기록했다.
(예제의 정확도는 0.68)
그래서 팀원들과 얘기를 나누며 2번째 방법을 시도해보기로 했다.
2. 다른 모델을 적용하는 방법
예제에선 Logistic Regression 과 KNN 알고리즘을 사용하여 모델에 적용을 시켰다.
좀 더 효과적인 알고리즘이 없을까 팀원들과 상의하던 도중 어떤 블로그의 글을 보게되었다.
이 블로그에서 소개하는 내용도 사진을 분류하는 모델을 만들기 위한 알고리즘이였다.정확도가 높은 Random Forest 와 Gradient Boosting 알고리즘을 사용하여 모델을 만들어보기로 했다.
Random Forest 의 알고리즘을 공부하고 사용법을 알아보던 중, 멘토님이 이 알고리즘에서 사용되는 중요한 파라미터를 몇가지 알려주셨다.
그래서 그 중 2가지를 먼저 설정해서 모델을 구성해보았다.
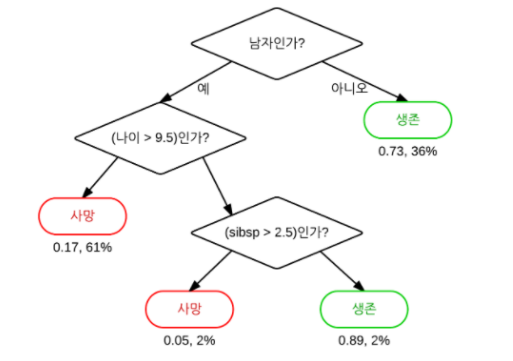
Random Forest Algorithmes : n개의 데이터를 추출하고 위 사진과 같은 식으로 분류하여 트리를 만들고,
이 작업을 반복하여 만들어놓은 트리들을 취합하여 결론을 얻는 알고리즘

n_estimators : 데이터를 분류하여 트리를 만드는 작업을 반복하는 횟수
-> 반복횟수가 많으면 현재 train 데이터 이외의 다른 데이터를 분류할 때 구분하지 못하는 경우가 생김
-> 반복횟수가 적으면 n개의 데이터만 추출하여 분류하는 알고리즘이기 때문에 정확하지 않음
max_depth : 트리의 최대 깊이
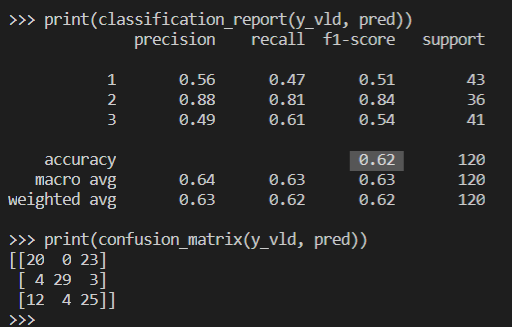
결과는 이렇다.
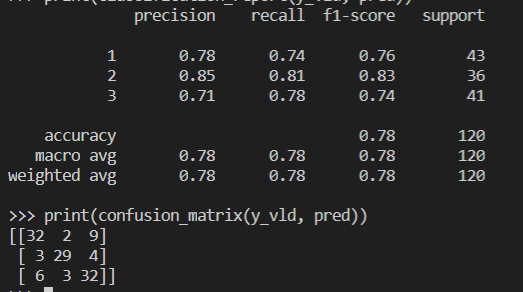
Random Forest 의 파라미터중에 criterion 이라는 옵션도 존재했는데, 이것은 분할기준을 설정할 수 있는 옵션이다.
default 값은 jini 라고 한다.
불확실성이 감소하도록 하는 분할 기준을 정해야 한다. 그래서 entropy라는 기준을 이용했다.

우리는 아직 log함수를 몰라서 정확하게는 이해하지 못했지만, 무질서에 대한 측도를 관찰하여 분할기준을 세운다.
jini 지수에서 정규화 과정을 거친다고 해서 entropy 를 이용해보기로 했다.
결과 :
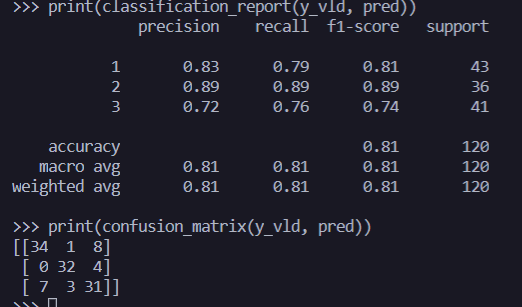
0.81 의 정확도를 얻을 수 있었다.
현상금사냥꾼 팀이 최종적으로 작성한 코드는 이러하다
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
train = pd.read_pickle("./A12_ml_train.pkl")
test = pd.read_pickle("./A12_ml_test.pkl")
train.shape, test.shape
train.head(5)
# X와 y로 나누기
# X는 한 픽셀을 Feature로 잡은 것 입니다.
# y는 label입니다.
#label1 -> 김밥
#label2 -> 떡볶이
#label3 -> 만두
X = train.drop(columns = ['label'])
y =train['label']
X_test= test.copy()
X.shape, y.shape
# 0번째 label 및 이미지 확인
# label1 -> 김밥
print(y[0])
plt.imshow(X.iloc[0].values.reshape(32,32,3)) # (32,32,3)으로 변환
plt.show()
# 200번째 label 및 이미지 확인
# label2 -> 떡볶이
print(y[200])
plt.imshow(X.iloc[200].values.reshape(32,32,3))
# 400번째 label 및 이미지 확인
# label3 -> 만두
print(y[400])
plt.imshow(X.iloc[400].values.reshape(32,32,3))
from sklearn.model_selection import train_test_split
X_train, X_vld, y_train, y_vld = train_test_split(X, y, random_state=42, test_size = .2)
X_train.shape, X_vld.shape, y_train.shape, y_vld.shape
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.svm import LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
algorithmes = [LogisticRegression(), KNeighborsClassifier(n_jobs=-1)]
##실험 파라미터 셋팅###
params = []
params.append([{
"solver" : ["saga"],
"penalty" : ["l1"],
"C" : [0.1, 5.0, 7.0, 10.0, 15.0, 20.0, 100.0]
},{
"solver" : ['liblinear'],
"penalty" : ["l2"],
"C" : [0.1, 5.0, 7.0, 10.0, 15.0, 20.0, 100.0]
}
]) #Logistic Regression 하이퍼 파라미터
params.append({
"p":[int(i) for i in range(1,3)],
"n_neighbors":[i for i in range(2, 6)]}) #KNN 하이퍼 파라미터
#### 5 - Fold Cross Validation & Accuracy
scoring = ['accuracy']
estimator_results = []
for i, (estimator, params) in enumerate(zip(algorithmes,params)):
gs_estimator = GridSearchCV(
refit="accuracy", estimator=estimator,param_grid=params, scoring=scoring, cv=5, verbose=1, n_jobs=4)
print(gs_estimator)
gs_estimator.fit(X, y)
estimator_results.append(gs_estimator)
print("Logistic의 가장 좋은 성능은 ",estimator_results[0].best_score_)
print("KNN의 가장 좋은 성능은 ",estimator_results[1].best_score_)
#가장 좋은 모델 설정
# model = estimator_results[0].best_estimator_
# print(RandomForestClassifier(n_estimators=100,max_depth=3))
model = RandomForestClassifier(n_estimators=100, max_depth=3, criterion = 'entropy')
model.fit(X_train, y_train)
# validation 예측
pred = model.predict(X_vld)
# validation set 성능 확인
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(y_vld, pred))
print(confusion_matrix(y_vld, pred))
# 결과 확인
print("True", y_vld.values)
print("Prediction", pred)
# 첫번째 데이터 True : 1(김밥)
# 첫번째 데이터 Label : 3(만두)
# 즉 모델이 김밥을 만두로 잘못예측한 개체이다.
plt.imshow(X_vld.iloc[0].values.reshape(32,32,3))
# 전체데이터로 학습하기
model.fit(X, y)
# 테스트 데이터 복사
X_test = test.copy()
final_pred = model.predict(X_test)
print(final_pred)
# final_pred를 npy로 저장합니다.
np.save("./submissin_file.npy", final_pred)
이 알고리즘을 이용하여 학습시킨 모듈로 주어진 A12_ml_test.pkl 데이터셋에 대한 label 값을 예측했다.
( 이 파일은 ndarray 배열을 파일로 저장한 것이다 - test_dataset의 label 데이터 )
XGBoost(Gradient Boosting) 알고리즘을 사용해서 모델에 적용해보려고 했지만
시간관계상 할 수 없었다. 이 점이 아쉬웠고, 데이터 전처리를 했으면 조금 더 높은 정확도를 얻을 수 있었을 것이라고 생각한다.
<느낀점>
아무준비 없이 예전에 배웠던 BigData 경험으로 대회에 나간다고 해서 친구들과 팀을꾸려 대회에 출전하긴 했으나, 예선에서 삽질만 하다가 겨우겨우 모델 하나 만들어 가까스로 본선에 진출했다.
예선전을 치룬 경험을 토대로 데이터 처리와 scikit-learn 모듈 사용법, 각종 알고리즘과 모델 학습법 등을 공부하며 본선을 준비했고, 준비한 만큼 결과가 나왔다. 이 점은 정말 다행이라고 생각한다. 팀원들과의 호흡도 예선때보다 훨씬 잘 맞아서 수월했다. 이번 대회는 나에게 도움을 많이 줬고, 나 스스로를 발전하게 했다. 좋은 경험이 돼서 좋았다.
(무엇보다 상금 70만원이 정말 행복하다.)